Code View
입력 데이터 생성
````python
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100, 2)
# data = np.array([[0.8, 0.0064],
# [0.12, 0.2848],
# [0.24, 0.7472],
# [0.68, 0.3488]])
data
````
Result
````planetext
array(\[\[0.76959259, 0.03105338\],
\[0.91933906, 0.8980492 \],
\[0.74919767, 0.46775453\],
\[0.66010482, 0.70532455\],
\[0.07347433, 0.31437638\],
\[0.52162755, 0.75475037\],
\[0.07618824, 0.5595569 \],
\[0.37694104, 0.88389 \],
\[0.59261356, 0.49140373\],
\[0.11567152, 0.32084966\],
\[0.81627506, 0.7724125 \],
\[0.7708446 , 0.98667885\],
\[0.57884267, 0.92658698\],
\[0.48815338, 0.04666865\],
\[0.07971729, 0.56926156\],
\[0.93371788, 0.20473364\],
\[0.71241481, 0.68994675\],
\[0.69855141, 0.55690579\],
\[0.87081581, 0.48218263\],
\[0.73239668, 0.47015934\],
\[0.48234206, 0.38374233\],
\[0.51407113, 0.3925697 \],
\[0.97608349, 0.58044996\],
\[0.67676596, 0.51393561\],
\[0.37059459, 0.99168193\],
\[0.17015263, 0.17250751\],
\[0.6980668 , 0.47156525\],
\[0.9674704 , 0.29847506\],
\[0.85297608, 0.15389296\],
\[0.99135256, 0.95353731\],
\[0.75749781, 0.05744834\],
\[0.5850026 , 0.69425312\],
\[0.35572734, 0.77261987\],
\[0.96259553, 0.10738437\],
\[0.0178066 , 0.68856146\],
\[0.78219693, 0.6523648 \],
\[0.18744908, 0.73438952\],
\[0.19713904, 0.56662014\],
\[0.11656314, 0.50708698\],
\[0.33800968, 0.03634445\],
\[0.64802194, 0.90416709\],
\[0.7668028 , 0.7619133 \],
\[0.55338936, 0.78892134\],
\[0.20716839, 0.95280491\],
\[0.47688275, 0.30063862\],
\[0.22233577, 0.02612442\],
\[0.21021643, 0.66526042\],
\[0.87039248, 0.75634555\],
\[0.91421121, 0.60350262\],
\[0.32014712, 0.61909491\],
\[0.03320721, 0.69900356\],
\[0.0806021 , 0.68826953\],
\[0.52828811, 0.78636528\],
\[0.49048742, 0.60616199\],
\[0.07021355, 0.64982408\],
\[0.21773879, 0.55571391\],
\[0.02119119, 0.62099936\],
\[0.75589808, 0.88236869\],
\[0.99479197, 0.98599938\],
\[0.35444256, 0.84292181\],
\[0.90941177, 0.30758414\],
\[0.87616741, 0.18060184\],
\[0.22973575, 0.50353087\],
\[0.33569227, 0.82710827\],
\[0.03575231, 0.86915894\],
\[0.59710596, 0.91274408\],
\[0.61854338, 0.06007 \],
\[0.69497861, 0.26505075\],
\[0.80347052, 0.93909288\],
\[0.8998602 , 0.34498986\],
\[0.96359265, 0.66780466\],
\[0.6180583 , 0.36145526\],
\[0.22507441, 0.24977 \],
\[0.82067222, 0.65858647\],
\[0.26533719, 0.50457457\],
\[0.20615695, 0.52028333\],
\[0.78530409, 0.23287443\],
\[0.81894409, 0.32542015\],
\[0.66607148, 0.0717416 \],
\[0.15435642, 0.57144805\],
\[0.60568206, 0.62824524\],
\[0.40981871, 0.51319754\],
\[0.14660118, 0.14759826\],
\[0.89091339, 0.12148139\],
\[0.48159329, 0.76667587\],
\[0.73766975, 0.76237422\],
\[0.32449576, 0.11193535\],
\[0.05351455, 0.37051478\],
\[0.15487227, 0.0884276 \],
\[0.40902546, 0.73216362\],
\[0.6227993 , 0.54298886\],
\[0.70489165, 0.60729615\],
\[0.43506953, 0.26510733\],
\[0.17818975, 0.41551925\],
\[0.07820619, 0.31987945\],
\[0.27646196, 0.00825832\],
\[0.30999502, 0.67284126\],
\[0.6372436 , 0.48780002\],
\[0.66962877, 0.44225145\],
\[0.48185839, 0.17663244\]\])
````
SOM 파라미터 설정
````python
map_width = 10
map_height = 10
lr = 0.1
num_iterations = 1000
# map_width = 2
# map_height = 2
# lr = 0.1
# num_iterations = 1000
````
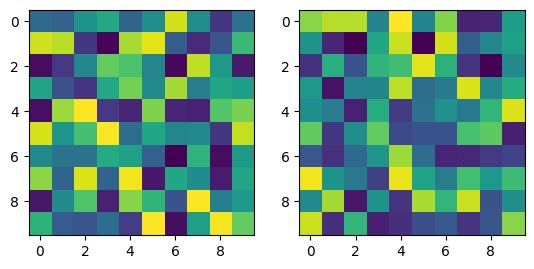
SOM 초기화
````python
som_map = np.random.rand(map_width, map_height, 2)
print(som_map.shape)
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.imshow(som_map[:,:,0])
ax2.imshow(som_map[:,:,1])
plt.show()
````
SOM 학습
````python
for i in range(num_iterations):
# 랜덤한 입력 데이터 선택
input_data = data[np.random.choice(data.shape[0])]
# 가장 유사한 뉴런 찾기
# 3D som_map과 input_data의 차이^2를 구하여 z축으로 모두 합한 거리
distances = np.sum((som_map - input_data) ** 2, axis=2)
# 위에서 구한 z축의 거리들 중 가장 작은 뉴런
winner = np.argmin(distances)
# 3D z축에서 선택된 가장 작은 뉴런을 2D map으로 맵핑한 좌표
x, y = np.unravel_index(winner, (map_width, map_height))
# 학습률 계산
learning_rate = lr * (1 - i/num_iterations)
# 뉴런 가중치 업데이트
for j in range(map_width):
for k in range(map_height):
dist = np.sqrt((x-j)**2 + (y-k)**2)
if dist < 3:
som_map[j, k] += learning_rate * (input_data - som_map[j, k])
````
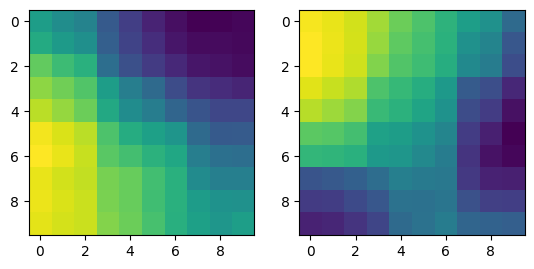
SOM 시각화
````python
print(som_map.shape)
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.imshow(som_map[:,:,0])
ax2.imshow(som_map[:,:,1])
plt.show()
````
### SOM 예제 코드 2[¶]()
Code View
Randomize 함수
````python
def randomize(A, rowcol=0):
"""
행렬 A를 행 혹은 열을 랜덤하게 섞기
rowcol: 0 혹은 없으면 행을 랜덤하게 섞기 (default)
1 이면, 열을 랜덤하게 섞기
"""
np.random.seed(int(sum([int(x) for x in str(time.time()) if x.isdigit()])))
if rowcol == 0:
m, n = A.shape
p = np.random.rand(m, 1)
p1, I = np.sort(p, axis=0), np.argsort(p, axis=0)
B = A[I, :]
return B.reshape(A.shape)
elif rowcol == 1:
Ap = A.T
m, n = Ap.shape
p = np.random.rand(m, 1)
p1, I = np.sort(p, axis=0), np.argsort(p, axis=0)
B = Ap[I, :]
return B.reshape(Ap.shape).T
````
Data Generator 함수
````python
def datagen(Nvec, mean_var):
m, c = mean_var.shape
if m != 3 or c != len(Nvec):
print("dimension not match, break")
return None
X = np.empty((0, 2))
for i in range(c):
np.random.seed(int(sum([int(x) for x in str(time.time()) if x.isdigit()])))
tmp = np.sqrt(mean_var[2, i]) * np.random.randn(Nvec[i], 2) # scaled by variance
mean = mean_var[0:2, i] # mean is a 2 by 1 vector
X = np.vstack((X, tmp + np.ones((Nvec[i], 2)) * mean))
return X
````
SOM 구현
````python
import os
import logging
import time
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib as mpl
# 마이너스 기호 표시 설정
mpl.rcParams['axes.unicode_minus'] = False
# 한글 폰트 설정 - Windows
# font_location = fm.findfont(fm.FontProperties(family='Malgun Gothic'))
# fm.FontProperties(fname=font_location)
# plt.rcParams['font.family'] = 'Malgun Gothic'
# 로거 수준을 ERROR로 설정하여 경고 메시지를 제거
matplotlib_logger = logging.getLogger("matplotlib")
matplotlib_logger.setLevel(logging.ERROR)
# 한글 폰트 설정 - Linux
font_dir = "/usr/share/fonts/truetype/nanum"
nanum_gothic_ttf = os.path.join(font_dir, "NanumGothic.ttf")
nanum_gothic = fm.FontProperties(fname=nanum_gothic_ttf)
# plt.rcParams["font.family"] = nanum_gothic.get_name()
plt.rcParams["axes.unicode_minus"] = False
def onces(rows, cols):
return np.ones((rows, cols))
# Parameters
N = 100 # 각 클러스터의 표본의 개수
N2 = N + N
eta = 0.2
means = np.array([[0.7, -0.8],
[0.7, -0.8]])
var = np.array([0.2, 0.2])
x = datagen([N, N], np.vstack((means, var))) # x: N2 by 2
x = randomize(x) # 행의 값을 랜덤하게 섞기
ncenter = 11 # 사용할 클러스터 뉴런의 개수
w = np.random.rand(ncenter, 2) - 0.5 * onces(ncenter, 2) # 초기 뉴런은 특징 공간상에 임의로 위치시킴
plt.figure()
plt.subplot(121)
plt.plot(x[:, 0], x[:, 1], 'r.', w[:, 0], w[:, 1], '*-')
plt.axis([-2, 2, -2, 2])
plt.title('초기화', fontproperties=nanum_gothic)
i = 1
iter = 1
converge = 0
while converge == 0:
dn = np.ones((ncenter, 1)) * x[i, :] - w
ddn = np.sum((dn * dn), axis=1) # ddn: ncenter by 1
istar = np.argmin(ddn)
if istar == 0:
w[[istar, istar + 1], :] = w[[istar, istar + 1], :] + eta * (np.ones((2, 1)) * x[i, :] - w[[istar, istar + 1], :])
elif istar == ncenter - 1:
w[[istar - 1, istar], :] = w[[istar - 1, istar], :] + eta * (np.ones((2, 1)) * x[i, :] - w[[istar - 1, istar], :])
else:
w[[istar - 1, istar, istar + 1], :] = w[[istar - 1, istar, istar + 1], :] + eta * (np.ones((3, 1)) * x[i, :] - w[[istar - 1, istar, istar + 1], :])
plt.subplot(122)
plt.plot(x[:, 0], x[:, 1], 'r.', x[i, 0], x[i, 1], 'o', w[:, 0], w[:, 1], '*-')
plt.title(f'Iteration = {iter}')
plt.pause(0.01)
i = (i + 1) % N2
iter += 1
if i == 0:
x = randomize(x) # 클러스터의 순서를 랜덤하게 섞는다.
i = 1 # 재배치된 입력으로 시작
if iter % 50 == 0:
eta *= 0.9
if iter >= 200:
converge = 1
plt
````
결과
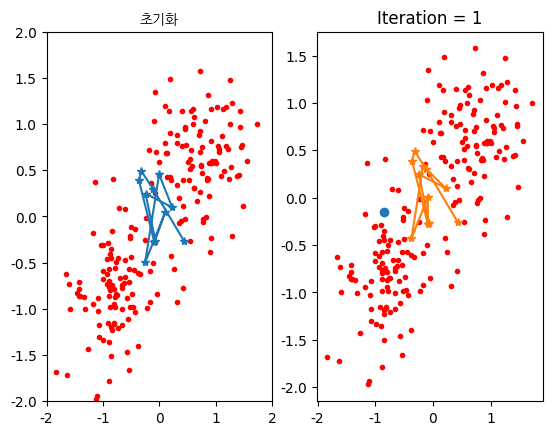
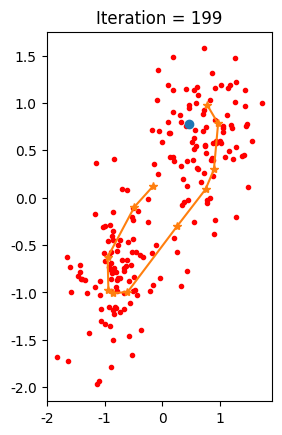
### SOM 예제 코드 3[¶]()