|
|
1 year ago | |
|---|---|---|
| dataset | 1 year ago | |
| images | 1 year ago | |
| README.md | 1 year ago | |
| gan.ipynb | 1 year ago | |
README.md
| layout | title | subtitle |
|---|---|---|
| default | 17. GAN | Deep Learning |
GAN
- 산업인공지능학과 대학원 2022254026 김홍열
적대적 생성 신경망(Generative Adversarial Networks)이란?
GAN이란 학습 데이터들의 분포를 학습해, 같은 분포에서 새로운 데이터를 생성할 수 있도록 DL 모델을 학습시키는 프레임워크다.
2014년 Ian Goodfellow가 개발했으며, Generative Adversarial Nets 논문에서 처음 소개되었다.
GAN은 생성자 와 구분자 로 구별되는 두가지 모델을 가지고 있는것이 특징이다.
생성자의 역할은 실제 이미지로 착각되도록 정교한 이미지를 만드는 것이고,
구분자의 역할은 이미지를 보고 생성자에 의해 만들어진 이미지인지 실제 이미지인지 알아내는 것이다.
모델을 학습하는 동안, 생성자는 더 진짜같은 가짜 이미지를 만들어내며 구분자를 속이려 하고,
구분자는 더 정확히 가짜/진짜 이미지를 구별할 수 있도록 노력한다.
이 ‘경찰과 도둑’ 게임은, 생성자가 학습 데이터들에서 직접 가져온 것처럼 보일정도로 완벽한 이미지를 만들어내고,
구분자가 생성자에서 나온 이미지를 50%의 확률로 가짜 혹은 진짜로 판별할 때, 균형상태에 도달하게 된다.
DCGAN이란?
DCGAN은 위에서 기술한 GAN에서 직접적으로 파생된 모델로,
생성자와 구분자에서 합성곱 신경망(convolution)과 전치 합성곱 신경망(convolution-transpose)을 사용했다는 것이 차이점이다
Radford와 그 외가 저술한 Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks 논문에서 처음 모델이 소개되었고,
지금은 대부분의 GAN모델이 DCGAN을 기반으로 만들어지는 중이다.
이전 GAN과 모델의 구조가 실제로 어떻게 다른지 확인을 해보자면, 먼저 구분자에서는 convolution 계층, batch norm 계층, 그리고 LeakyReLU 활성함수가 사용되었다.
클래식한 GAN과 마찬가지로, 구분자의 입력 데이터는 3x64x64 의 이미지이고, 출력값은 입력 데이터가 실제 데이터일 0~1사이의 확률값이다.
다음으로, 생성자는 convolutional-transpose 계층, 배치 정규화(batch norm) 계층, 그리고 ReLU 활성함수가 사용되었다.
입력값은 역시나 정규분포에서 추출한 잠재공간 벡터 z이고, 출력값은 3x64x64 RGB 이미지이다.
이때, 전치 합성곱 신경망은 잠재공간 벡터로 하여금 이미지와 같은 차원을 갖도록 변환시켜주는 역할을 한다.
예제 코드¶
Import
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# 코드 실행결과의 동일성을 위해 무작위 시드를 설정합니다
manualSeed = 999
#manualSeed = random.randint(1, 10000) # 만일 새로운 결과를 원한다면 주석을 없애면 됩니다
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Hyper Parameters
# 데이터셋의 경로
dataroot = "./dataset/img_align_celeba_png"
# dataloader에서 사용할 쓰레드 수
workers = 2
# 배치 크기
batch_size = 128
# 이미지의 크기입니다. 모든 이미지를 변환하여 64로 크기가 통일됩니다.
image_size = 64
# 이미지의 채널 수로, RGB 이미지이기 때문에 3으로 설정합니다.
nc = 3
# 잠재공간 벡터의 크기 (예. 생성자의 입력값 크기)
nz = 100
# 생성자를 통과하는 특징 데이터들의 채널 크기
ngf = 64
# 구분자를 통과하는 특징 데이터들의 채널 크기
ndf = 64
# 학습할 에폭 수
num_epochs = 5
# 옵티마이저의 학습률
lr = 0.0002
# Adam 옵티마이저의 beta1 하이퍼파라미터
beta1 = 0.5
# 사용가능한 gpu 번호. CPU를 사용해야 하는경우 0으로 설정하세요
ngpu = 1
데이터셋(Celeb-A Faces dataset)
본 튜토리얼에서 사용할 데이터는 Celeb-A Faces dataset 로,
해당 링크를 이용하거나 Google Drive 에서 데이터를 받을 수 있다.
데이터를 받으면 img_align_celeba.zip 라는 파일이 있다.
다운로드가 끝나면 celeba 이라는 폴더를 새로 만들고, 해당 폴더에 해당 zip 파일을 압축해제 해주시면 된다.
압축 해제 후, 위에서 정의한 dataroot 변수에 방금 만든 celeba 폴더의 경로를 넣는다.
위의 작업이 끝나면 celeba 폴더의 구조는 다음과 같아야 한다.
./dataset/img_align_celeba_png
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
-> 537394.jpg
...
예제 코드¶
Celeb-A Faces dataset
# 우리가 설정한 대로 이미지 데이터셋을 불러와 봅시다
# 먼저 데이터셋을 만듭니다
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# dataloader를 정의해봅시다
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# GPU 사용여부를 결정해 줍니다
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 학습 데이터들 중 몇가지 이미지들을 화면에 띄워봅시다
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))

가중치 초기화
# ``netG`` 와 ``netD`` 에 적용시킬 커스텀 가중치 초기화 함수
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
생성자
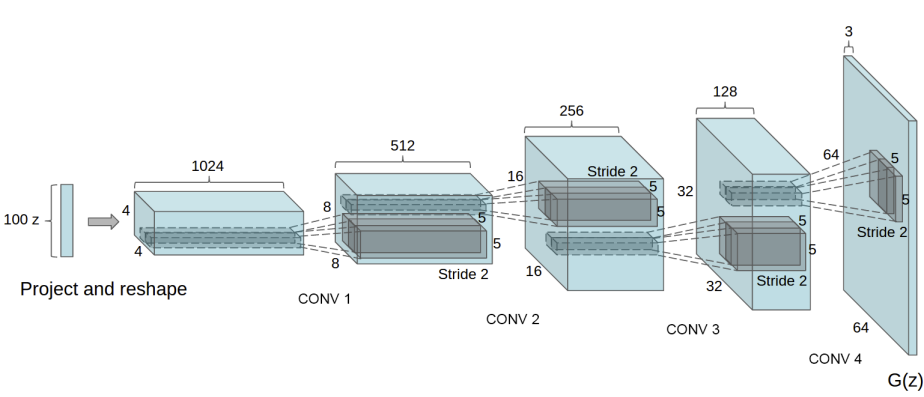
G 는 잠재 공간 벡터 z를, 데이터 공간으로 변환시키도록 설계되었다.
우리에게 데이터라 함은 이미지이기 때문에, z를 데이터공간으로 변환한다는 뜻은,
학습이미지와 같은 사이즈를 가진 RGB 이미지를 생성하는것과 같다 (예. 3x64x64).
실제 모델에서는 스트라이드(stride) 2를 가진 전치 합성곱 계층들을 이어서 구성하는데,
각 전치 합성곱 계층 하나당 2차원 배치 정규화 계층과 relu 활성함수를 한 쌍으로 묶어서 사용한다.
생성자의 마지막 출력 계층에서는 데이터를 tanh 함수에 통과시키는데, 이는 출력 값을 [−1,1] 사이의 범위로 조정하기 위해서다.
이때 배치 정규화 계층을 주목할 필요가 있는데, DCGAN 논문에 의하면, 이 계층이 경사하강법(gradient-descent)의 흐름에 중요한 영향을 미치는 것으로 알려져 있다.
아래의 그림은 DCGAN 논문에서 가져온 생성자의 모델 아키텍쳐다.
예제 코드¶
Generator
# 생성자 코드
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력데이터 Z가 가장 처음 통과하는 전치 합성곱 계층입니다.
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# 위의 계층을 통과한 데이터의 크기. ``(nc) x 64 x 64``
)
def forward(self, input):
return self.main(input)
# 생성자를 만듭니다
netG = Generator(ngpu).to(device)
# 필요한 경우 multi-GPU를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# 모든 가중치의 평균을 0( ``mean=0`` ), 분산을 0.02( ``stdev=0.02`` )로 초기화하기 위해
# ``weight_init`` 함수를 적용시킵니다
netG.apply(weights_init)
# 모델의 구조를 출력합니다
print(netG)
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
구분자
앞서 언급했듯, 구분자 D는 입력 이미지가 진짜 이미지인지 (혹은 반대로 가짜 이미지인지) 판별하는 전통적인 이진 분류 신경망으로 볼 수 있다.
이때 D는 3x64x64 이미지를 입력받아, Conv2d, BatchNorm2d, 그리고 LeakyReLU 계층을 통과시켜 데이터를 가공시키고,
마지막 출력에서 Sigmoid 함수를 이용하여 0~1 사이의 확률값으로 조정한다.
이 아키텍쳐는 필요한 경우 더 다양한 레이어를 쌓을 수 있지만, 배치 정규화와 LeakyReLU, 특히 보폭이 있는 (strided) 합성곱 계층을 사용하는 것에는 이유가 있다.
DCGAN 논문에서는 보폭이 있는 합성곱 계층을 사용하는 것이 신경망 내에서 스스로의 풀링(Pooling) 함수를 학습하기 때문에,
데이터를 처리하는 과정에서 직접적으로 풀링 계층( MaxPool or AvgPooling)을 사용하는 것보다 더 유리하다.
또한 배치 정규화와 leaky relu 함수는 학습과정에서 G와 D가 더 효과적인 경사도(gradient)를 얻을 수 있다.
Discriminator
# 구분자 코드
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력 데이터의 크기는 ``(nc) x 64 x 64`` 입니다
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf) x 32 x 32``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*2) x 16 x 16``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*4) x 8 x 8``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. ``(ndf*8) x 4 x 4``
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# 구분자를 만듭니다
netD = Discriminator(ngpu).to(device)
# 필요한 경우 multi-GPU를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# 모든 가중치의 평균을 0( ``mean=0`` ), 분산을 0.02( ``stdev=0.02`` )로 초기화하기 위해
# ``weight_init`` 함수를 적용시킵니다
netD.apply(weights_init)
# 모델의 구조를 출력합니다
print(netD)
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
loss function, optimizer
# ``BCELoss`` 함수의 인스턴스를 초기화합니다
criterion = nn.BCELoss()
# 생성자의 학습상태를 확인할 잠재 공간 벡터를 생성합니다
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# 학습에 사용되는 참/거짓의 라벨을 정합니다
real_label = 1.
fake_label = 0.
# G와 D에서 사용할 Adam옵티마이저를 생성합니다
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
Train
# 학습 과정
# 학습상태를 체크하기 위해 손실값들을 저장합니다
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# 에폭(epoch) 반복
for epoch in range(num_epochs):
# 한 에폭 내에서 배치 반복
for i, data in enumerate(dataloader, 0):
############################
# (1) D 신경망을 업데이트 합니다: log(D(x)) + log(1 - D(G(z)))를 최대화 합니다
###########################
## 진짜 데이터들로 학습을 합니다
netD.zero_grad()
# 배치들의 사이즈나 사용할 디바이스에 맞게 조정합니다
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label,
dtype=torch.float, device=device)
# 진짜 데이터들로 이루어진 배치를 D에 통과시킵니다
output = netD(real_cpu).view(-1)
# 손실값을 구합니다
errD_real = criterion(output, label)
# 역전파의 과정에서 변화도를 계산합니다
errD_real.backward()
D_x = output.mean().item()
## 가짜 데이터들로 학습을 합니다
# 생성자에 사용할 잠재공간 벡터를 생성합니다
noise = torch.randn(b_size, nz, 1, 1, device=device)
# G를 이용해 가짜 이미지를 생성합니다
fake = netG(noise)
label.fill_(fake_label)
# D를 이용해 데이터의 진위를 판별합니다
output = netD(fake.detach()).view(-1)
# D의 손실값을 계산합니다
errD_fake = criterion(output, label)
# 역전파를 통해 변화도를 계산합니다. 이때 앞서 구한 변화도에 더합니다(accumulate)
errD_fake.backward()
D_G_z1 = output.mean().item()
# 가짜 이미지와 진짜 이미지 모두에서 구한 손실값들을 더합니다
# 이때 errD는 역전파에서 사용되지 않고, 이후 학습 상태를 리포팅(reporting)할 때 사용합니다
errD = errD_real + errD_fake
# D를 업데이트 합니다
optimizerD.step()
############################
# (2) G 신경망을 업데이트 합니다: log(D(G(z)))를 최대화 합니다
###########################
netG.zero_grad()
label.fill_(real_label) # 생성자의 손실값을 구하기 위해 진짜 라벨을 이용할 겁니다
# 우리는 방금 D를 업데이트했기 때문에, D에 다시 가짜 데이터를 통과시킵니다.
# 이때 G는 업데이트되지 않았지만, D가 업데이트 되었기 때문에 앞선 손실값가 다른 값이 나오게 됩니다
output = netD(fake).view(-1)
# G의 손실값을 구합니다
errG = criterion(output, label)
# G의 변화도를 계산합니다
errG.backward()
D_G_z2 = output.mean().item()
# G를 업데이트 합니다
optimizerG.step()
# 훈련 상태를 출력합니다
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 이후 그래프를 그리기 위해 손실값들을 저장해둡니다
G_losses.append(errG.item())
D_losses.append(errD.item())
# fixed_noise를 통과시킨 G의 출력값을 저장해둡니다
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
Result
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# G의 학습과정 시각화
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())
## 진짜 이미지 vs 가짜 이미지
# dataloader에서 진짜 데이터들을 가져옵니다
real_batch = next(iter(dataloader))
# 진짜 이미지들을 화면에 출력합니다
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 가짜 이미지들을 화면에 출력합니다
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()



참고¶
- GAN - Google
- ChatGPT
- 파이토치 GAN 튜토리얼