7.3 KiB
| layout | title | subtitle |
|---|---|---|
| default | 12. VGGNet | Deep Learning |
VGG Net
- 산업인공지능학과 대학원 2022254026 김홍열
VGG net 이란
VGGNet은 컴퓨터 비전 분야에서 널리 사용되는 심층 합성곱 신경망(Convolutional Neural Network, CNN)이다.
VGGNet은 K. Simonyan과 A. Zisserman이 "Very Deep Convolutional Networks for Large-Scale Image Recognition"이라는 논문에서 제안한 합성곱 신경망 모델이다.
이 아키텍처는 ImageNet에서 92.7%의 상위 5개 테스트 정확도를 달성했으며, 이는 1000개의 클래스에 속하는 1400만 개 이상의 이미지를 포함하고 있습다.

VGGNet은 여러 개의 작은 (3x3) 커널을 가진 합성곱 계층과 2x2 풀링 계층으로 구성되어 있으며,
이를 여러 번 반복하여 깊은 네트워크를 구성된다.
가장 유명한 버전은 VGG16과 VGG19이다.
VGG16 아키텍처의 주요 특징
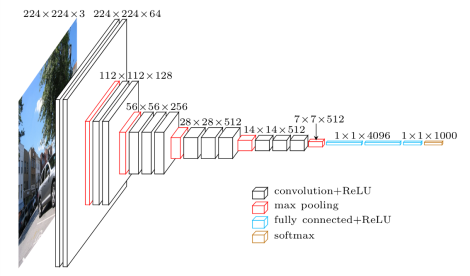
모델에 대한 입력은 고정 크기인 224×224x3 RGB 이미지이다.
전처리는 각 픽셀에서 훈련 데이터 세트에서 계산된 평균 RGB 값을 빼는 것이다.
이미지는 매우 작은 수용 필드인 3 × 3의 필터가 있는 여러 개의 합성곱(Conv.) 계층을 통해 실행된다.
일부 구성에서는 1 × 1 합성곱 필터도 사용한다.
합성곱의 보폭은 1 픽셀로 고정되어 있다.
공간 풀링은 일부 Conv. 계층 뒤에 있는 5개의 최대 풀링 계층에 의해 수행된다.
아키텍처에는 세 개의 완전 연결(FC) 계층이 포함되어 있으며, 처음 두 FC는 각각 4096개의 채널을 가지고 있고, 세 번째 FC는 1000개의 채널을 가지고 있다.
마지막 계층은 소프트맥스 계층이다.
데이터셋 (Cifar10)

-
이미지 수와 카테고리: 데이터셋은 총 60,000개의 이미지로 구성되어 있으며, 이 중 50,000개는 학습용, 10,000개는 테스트용으로 분리되어 있다.
-
10가지 카테고리는 각각 공통된 대상을 나타낸다.
-
이 카테고리들은 '비행기', '자동차', '새', '고양이', '사슴', '개', '개구리', '말', '배', '트럭' 등이다.
-
모든 이미지는 32x32 픽셀 크기의 3채널 컬러(RGB) 이미지
예제 코드¶
Cifar10 Dataset
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# CIFAR-10 데이터셋 로드
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# 데이터 정규화
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# 원-핫 인코딩
Y_train = to_categorical(y_train, 10)
Y_test = to_categorical(y_test, 10)
VGGNet Structure
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
# 첫 번째 블록
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 두 번째 블록
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 세 번째 블록
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 네 번째 블록
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 다섯 번째 블록
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 완전 연결 계층
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(10, activation='softmax')) # CIFAR-10 데이터셋을 위한 출력 계층
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
예제 코드¶
Train
model.fit(X_train, Y_train, batch_size=32, epochs=10, validation_split=0.2)
model.save('vgg16.model')
Result
Epoch 1/10
1250/1250 [==============================] - 1253s 1s/step - loss: 2.3029 - accuracy: 0.0996 - val_loss: 2.3027 - val_accuracy: 0.0980
Epoch 2/10
1250/1250 [==============================] - 1184s 947ms/step - loss: 2.3027 - accuracy: 0.0996 - val_loss: 2.3028 - val_accuracy: 0.0952
Epoch 3/10
1250/1250 [==============================] - 1435s 1s/step - loss: 2.3028 - accuracy: 0.0993 - val_loss: 2.3027 - val_accuracy: 0.0952
Epoch 4/10
1250/1250 [==============================] - 1336s 1s/step - loss: 2.3028 - accuracy: 0.0992 - val_loss: 2.3027 - val_accuracy: 0.0980
Epoch 5/10
1250/1250 [==============================] - 1411s 1s/step - loss: 2.3028 - accuracy: 0.0997 - val_loss: 2.3028 - val_accuracy: 0.0952
Epoch 6/10
1250/1250 [==============================] - 1310s 1s/step - loss: 2.3028 - accuracy: 0.0992 - val_loss: 2.3027 - val_accuracy: 0.1014
Epoch 7/10
1250/1250 [==============================] - 1282s 1s/step - loss: 2.3027 - accuracy: 0.0986 - val_loss: 2.3027 - val_accuracy: 0.1022
Epoch 8/10
1250/1250 [==============================] - 1300s 1s/step - loss: 2.3028 - accuracy: 0.0981 - val_loss: 2.3027 - val_accuracy: 0.1025
Epoch 9/10
1250/1250 [==============================] - 1360s 1s/step - loss: 2.3027 - accuracy: 0.1002 - val_loss: 2.3029 - val_accuracy: 0.0952
Epoch 10/10
1250/1250 [==============================] - 1400s 1s/step - loss: 2.3027 - accuracy: 0.0996 - val_loss: 2.3026 - val_accuracy: 0.1016
<keras.src.callbacks.History at 0x241b73a02e0>
INFO:tensorflow:Assets written to: vgg16.model\assets
INFO:tensorflow:Assets written to: vgg16.model\assets
예제 코드¶
Evalute
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Result
Test loss: 2.3026254177093506
Test accuracy: 0.10000000149011612
결론
-
VGGNet은 3x3 filter로 모든 Conv Layer에 사용함.
-
더 많은 ReLU함수를 사용하여 비선형성을 확보할 수 있음.
-
VGGNet은 VGG16, VGG19 등의 모델들이 있음.
참고¶
- VGGNet - Google
- ChatGPT